CFA level2 Quant 유OO 강사님 practice problem 및 CFA 홈페이지 문제 풀이 질의
3가지 문제에 대해서 질문 드립니다.
1. [Reading 3: time-series analysis]
practice problem 의 문제 35번입니다.
(exhibit5)

Based on Exhibit 5, which single time-series model would most likely be appropriate for Busse to use in predicting the future stock price of Company 3?
A Log-linear trend model
B First-differenced AR(2) model
C First-differenced log AR(1) mode
해당 질문에서 답이 C입니다.
Trend Model 사용 시 serial correlation이 존재하고, Exponential trend를 가지고 있어서 log AR모델을 사용해야하는 건 이해가 됩니다만
왜 'first-differenced'된 모델을 사용해야하는 건지 이해가 안 갑니다.
제가 이해하기로는 first-differencing은 unit root인 경우 이를 교정해서 변형된 AR모델로 만들기 위한 과정인 것인데, 왜 unit root가 아닌 company 3에 대해서 first-differencing을 해야하나요?
제가 first-differencing에 대해 잘못 이해하고 있는 부분이 있다면 말씀 부탁드립니다.
2. [CFA 공식 홈페이지 제공 practice 문제 Quant(1) 102번]
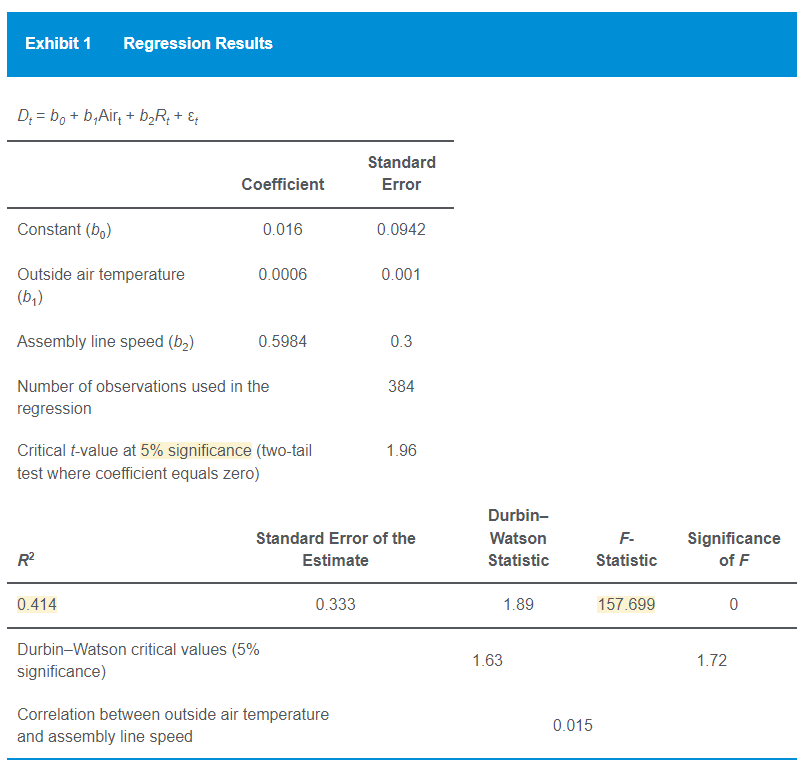
The results reported in Exhibit 1 are most accurately interpreted as indicating that:
-
the reported R2 is spurious.
-
multicollinearity is not present.
-
the regression coefficients have inflated standard errors.
해당 문제에서 답은 B이고, 그 해설은 다음과 같습니다.
-> pairwise correleation이 낮음. 전형적인 multicollinearity의 증상 (높은 R^2, significant한 F값, nonsignificant한 coeefficient 값)이 나타나지 않기 때문에 multicollinearity가 없다.
exhibit1에서 pairwise correlation = 0.015, F값 = 157.699, R^2값 = 0.414 인데, R^2이 0.414면 낮다고 보기는 어렵지 않나요??
어느정도 수치부터 high고 어느정도 수치부터 low라고 봐야 하는 건지 헷갈립니다. 그냥 주관적으로 판단하는 수 밖에 없나요? 대략적인 기준이라도 없는지 질의 드립니다.
그리고 coefficient도 standard error로 나눴을 때 값이
b0, b1, b2 각각 순서대로 값이 0.1699, 0.6, 1.9947로, 3개 중 2개가 5% critical t-value를 넘지 못해서 significant 하지 않은 것으로 계산되는데
이런 상황에서 어떻게 바로 multicollinearity가 없다고 단정 지을 수 있는지 의문입니다.
3. [CFA 공식 홈페이지 제공 practice 문제 Quant(6) 6번]

If Martin were to use a k-nearest neighbor model, the value for k would be closest to:
-
5.
-
50.
-
300.
이 문제 답은 A이고, 풀이는 다음과 같습니다.
Martin wants to classify clients into five different clusters (five strategic investment portfolios), according to the retirement portfolio that is most suitable for their needs.
KNN 모델의 경우 K를 target값의 개수로 잡는게 아니라, 모델링 하는 사람의 주관적인 판단으로 적정값을 지정해야하는 것 아닌가요?
K means clustering의 경우 K를 target 개수로 잡는 것은 알겠으나 KNN에는 안 맞는 것 같아서 문제 오류인가 싶어서 문의 드립니다.
댓글
안녕하세요. 이패스코리아입니다.
강사님께 문의 후 답변 전달 드리겠습니다.
감사합니다.
안녕하세요. 이패스코리아입니다.
문의하신 강사님 답변입니다.
질문에 감사드립니다.
#1 ==>님의 말대로 log AR모델을 사용해야 합니다.
그런데, first-differenced를 해야 할 때도 있고 하지 않을 때도 있습니다.
만약에 'D. log AR(1) model'이 있다면 C와 D 중에서 고민해보겠지만, D가 없으니 정답은 C일 수 밖에 없습니다.
#2. 'multicollinearity'는 독립변수간에 선형관계가 높은 경우입니다. 그 증상은 님의 말대로 "높은 R^2 & significant한 F값 & nonsignificant한 coefficient 값"입니다.
"pairwise correlation = 0.015"로 낮아 multicollinearity가 존재하지 않습니다. "F값 = 157.699, R^2값 = 0.414"라서 multicollinearity의 증상이 있지 않느냐는 주장이신데...
F값이 크면, R^2값은 일반적으로 큽니다. 따라서 F값의 크기와 R^2값의 크기는 동일한 의미를 지닙니다. 이제 남은 것은 t-값입니다. 이를 통해 개별 독립변수가 significant한지 확인할 수 있습니다. 근데 B2의 t-값은 1.995 (=0.5984/0.3)로 significant 합니다. 즉 증상 중 한 가지가 만족하지 않습니다. 그러므로 multicollinearity가 존재하지 않는다고 결론지어야 합니다. 참고로 'R^2값 = 0.414'이 낮다거나 높다고 판단할 수는 없습니다.
#3 ==> 님의 말이 맞습니다. 문제에서 "If Martin were to use a k-nearest neighbor model, "을 "If Martin were to use a k means clustering model, "로 바꿔야 합니다.
이상입니다.
댓글을 남기려면 로그인하세요.