모의고사 연습하면서 발생한 질문 몇 가지
안녕하세요, 모의고사 연습하면서 궁금한 점이 많이 발생하여 질문드립니다.
1. 현재 제 jupyter notebook에서는 엑셀 파일 불러내기, fillna 함수 시 inplace=True 등을 입력하면 오류가 발생합니다. 시험 환경에서는 이런 오류가 발생하지 않도록 세팅되어져 있는 거 맞나요?
2. 공유주신 모의고사 답안지랑 제 답안지를 비교했을 때 과정은 동일한데 마지막 정확도 및 f1-score 평가에서는 숫자가 일부 다릅니다. 0.1~2정도 차이가 나는데, 어디서 잘못된 건지 확인이 불가합니다. 이렇게 숫자가 완전히 일치하지 않을 수가 있나요?
3. 추가로 시험 중 오픈북은 주어진 라이브러리에서만 가능하다고 들었는데, 그 라이브러리 홈페이지 안에서 접근 제한된 페이지는 별도로 없는건가요?
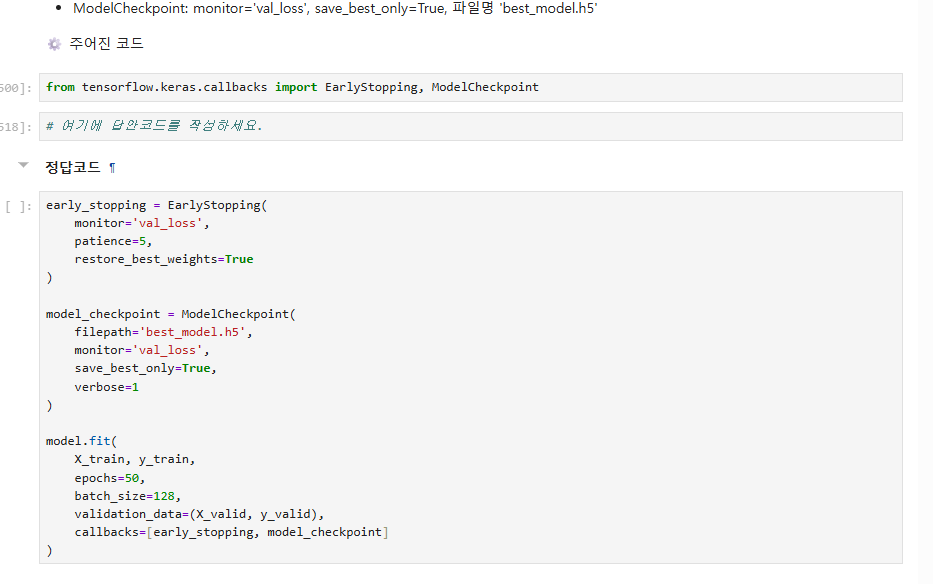
4. callbacks 관련 함수에서
EarlyStopping은 restore_best_weight=True를 무조건 입력하고,
ModelCheckPoint는 save_best_only=True, verbose=1을 무조건 입력해야 하나요?
> 의문이 든 이유는 ‘파란책 2회 모의고사 13번에서 ModelCheckpoint의 옵션에 restore_best_weights=True’라고 기재되어 있는데, 정답 코드를 보니 저 옵션은 EarlyStopping에 기재되어 있고 ModelCheckPoint에는 save_best_only가 기입되어져 있더라구요
5. 모델 측정 지표 결과를 출력 할 때,
강사님의 답안지처럼
print('rfr accuracy ' , accuracy_score(y_valid, rfc_predict))의 형태로 출력해야 하나요?
특정한 요구가 없으면 print(accuracy_score(y_valid, rfc_predict))로 답만 나오도록 출려해도 될까요?
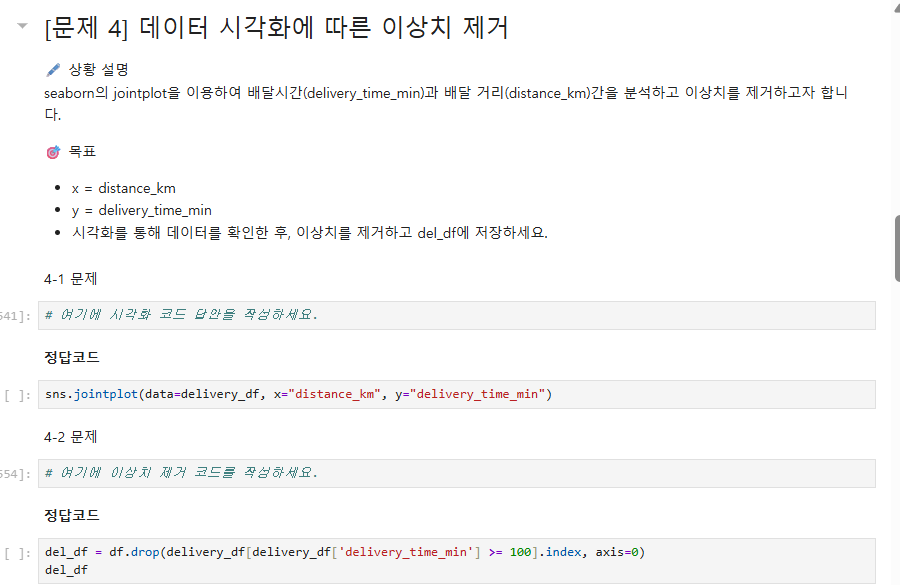
6. 그리고 파란책 제 2회 모의고사에서 이상치 제거하는 함수 중 df.drop이 아니라 delivery_df.drop이 와야 하는 거 아닌가용?
del_df = df.drop(delivery_df~
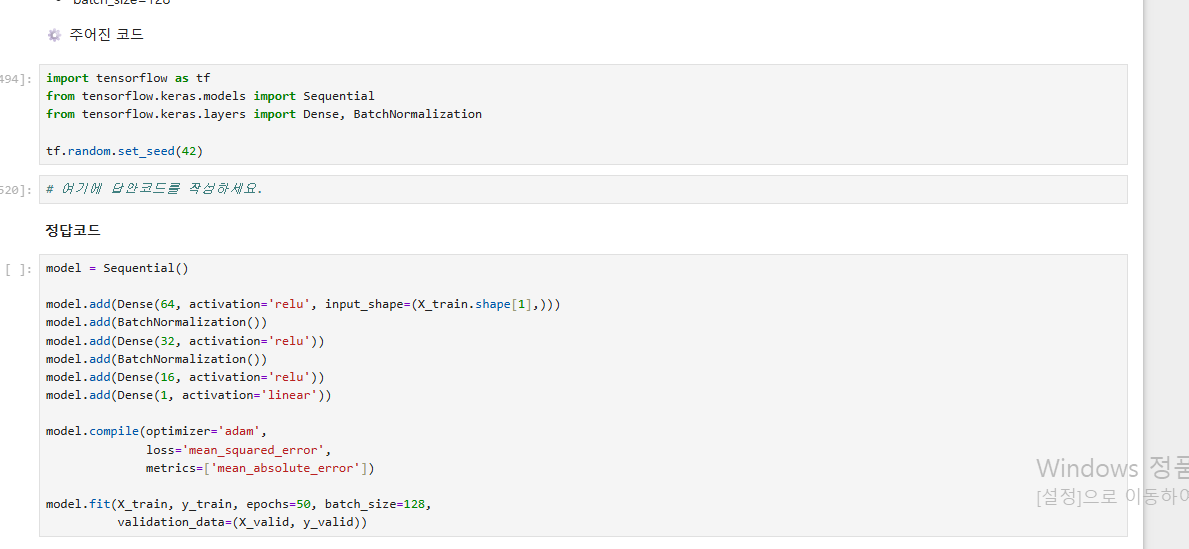
7.그리고 아래 코드에서 validation_data = (X_test, y_valid)아닌가요? X_valid는 스케일링 적용 전이고, X_test는 스케일링 적용 후 입니다. 아래는 첨부주신 파란책 제 2회 모의고사 정답 코드입니다. 교재랑 실습 코드 답이 모두 달라서 혼란스러운데, 어떤 것이 답인가요? 감사합니다!
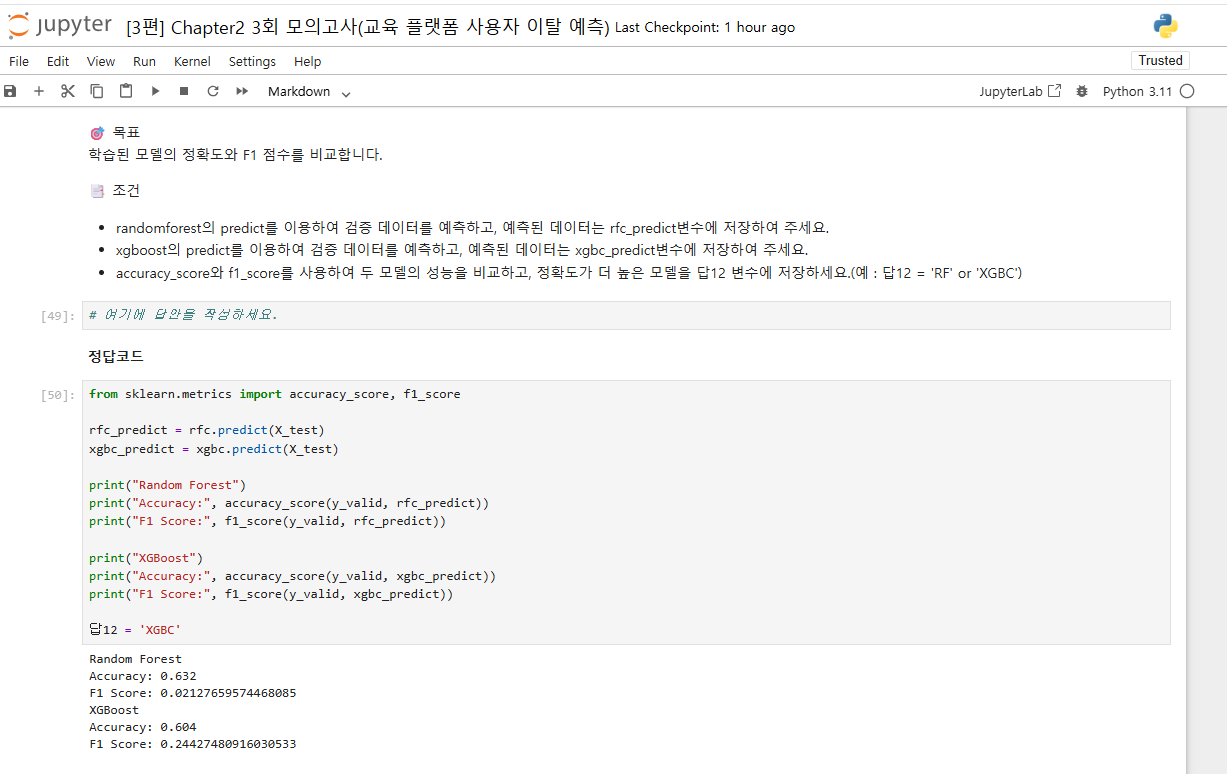
8. 아래 답이 RF가 아닌 XGBC인 이유가 있나요? 첨부한 코드 수정없이 엔터해서 값을 불러냈는데
accuracy_score는 rf가 더 높고, f1_score는 xgbc가 더 높습니다.
이럴 경우 ‘정확도’가 더 높은 걸 선택하라고 할 때 어떤 지표를 기준으로 작성해야 하나요?
어떻게 판단해야 답을 xgbc로 이끌어낼 수 있는지 궁금합니다. 저는 단순히 정확도라고 해서 accuracy_score만을 기준으로 판단하여 rf가 답이라고 생각했습니다.
9. 해당 문제의 딥 모델 설계 중 model.fit(validation_data=( , ))를 따로 기입하지 않은 이유가 있나용?
기입하면 오답 처리하나요?
10.
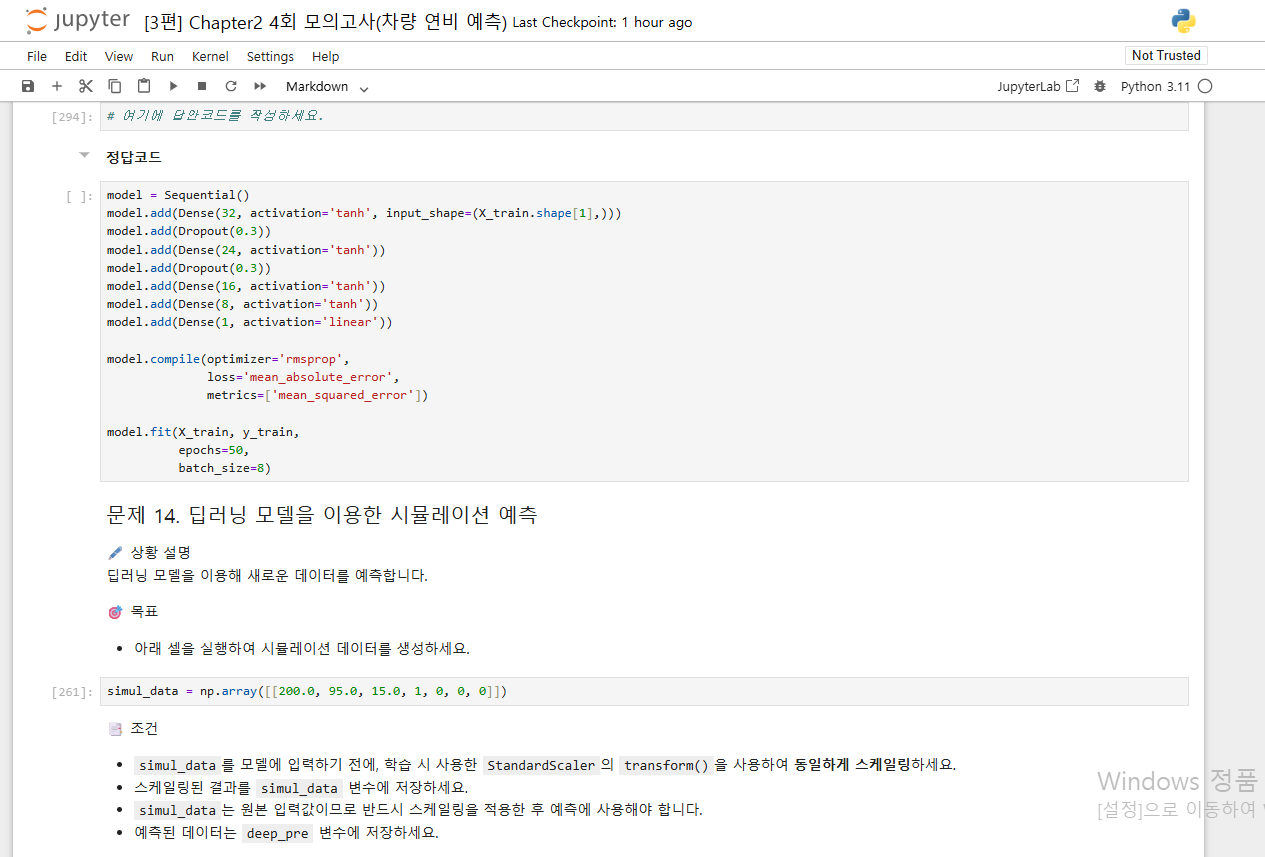
혹시 아래에서
pre_df = churn_df.dropna(subset=['years_experience', ‘salary’])대신에
pre_df=curn_df.dropna()만 입력해도 될까요?
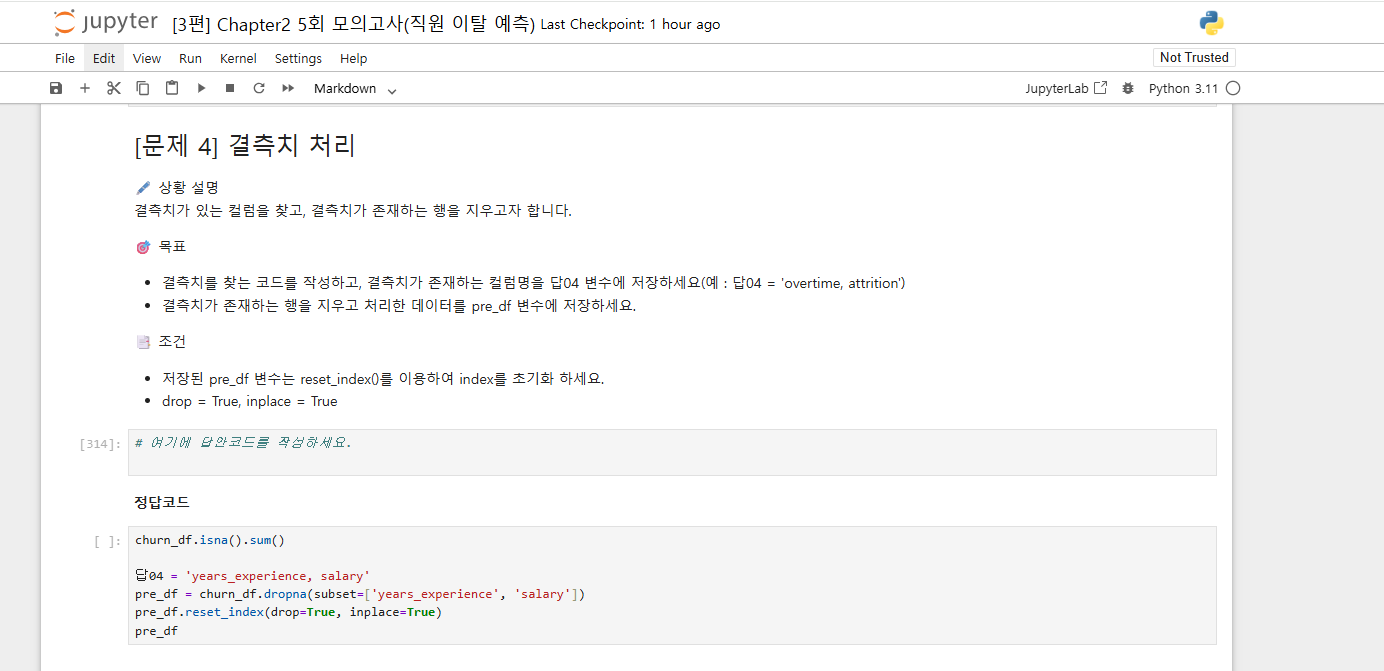
11. 아래 모델에서도 validation_data를 따로 기입하지 않은 이유가 있나용?
파란책 기준 제 2회 모의고사에서는 validation_data가 있었는데, 6g회에서는 없네요ㅠㅠ
상황에 따라 다른 것 같은데, 그 판단 기준을 모르겠습니다.
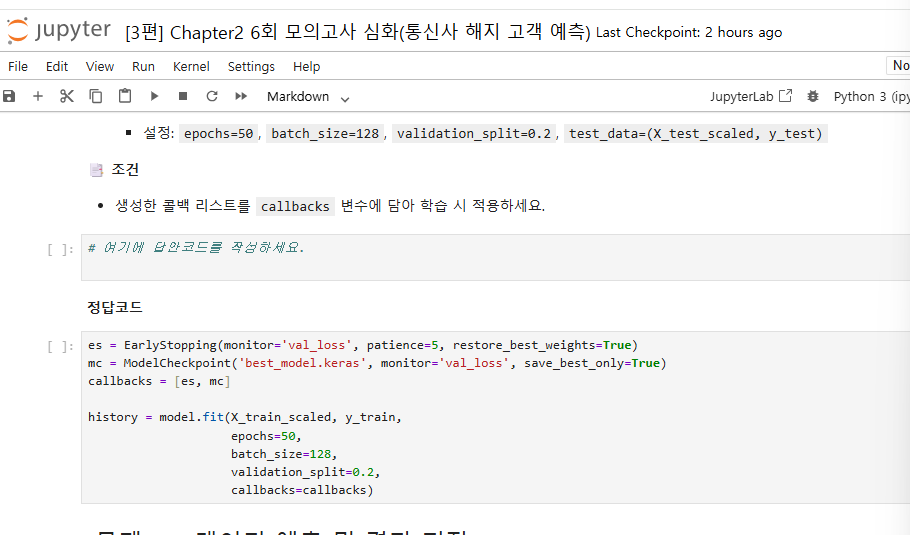
11번
혹시 해당 코드에서 원본 보존을 위한 코드를 따로 치는 이유가 있나요?
이전 파란책 모의고사에서는 원본 보존없이 바로 fillna와 drop을 수행했는데,
해당 모의고사에서는 왜 원본 보존을 위한 코드가 들어갔는지 궁금합니다.
13.
빨간책 1회 모의고사 13번 문제 (딥러닝 설계)입니다
13.1) 문제 모델구조 중 가장 마지막에 ‘출력층 : Dense 레이어, 1개 노드(가격을 예측하므로)’라고 되어 있습니다.
그에 대한 답으로 강의에서는 model.add(Dense(1, activation = ‘linear’))이라고 입력했고, 교재에서는 model.add(Dense(1))이라고만 입력되어 있습니다. 둘 다 동일한 건가요? 다르다면 어떤 것이 정답인가요?
13.2) 또한 문제 중에 validation_data로 X_valid_scaled, y_valid를 사용하여 검증 손실도 함께 확인하라고 되어있습니다.
이 말은 model.fit(X~ , y~, epochs~, batch_size,~, validation_data = (X_valid_scaled, y_valid))처럼 validation_data를 추가하라는 말인건지, 아니면 교재처럼 model.evaluation(X_valid_scaled, y_valid)의 명령을 더 추가해야하는 건지 모르겠습니다 (강의에서는 후자 과정을 생략하고 전자 과정까지만 기입했으나, 답지에서는 후자 과정이 기입되어 있어 헷갈립니다.
질문이 많아졌네요..감사합니다!
14번
이어서, 실전 책 1회 14번에서 predicted_price가 인강에서는 1211.2705로 산출되었는데 첨부주신 정답 코드 파일에서는 91.90으로 나옵니다.
왜 가격이 달라졌는지 궁금합니다 ㅠㅠ
인강, 첨부주신 강의 자료, 교재 답지..마다 답이 달라서 초보자가 받아들이기에는 너무 혼란스럽습니다. 조금만 다른 명령어를 기입해도, 다른 결과값이 나오는 영역에서..어떤 것이 정답인지 판단이 불가합니다. 긴 글 읽어주셔서 감사합니다.
댓글
안녕하세요.
문의 주신 내용이 많아서 항목별로 정리해 답변드립니다.
1. 로컬 Jupyter Notebook에서 fillna에 inplace 옵션을 사용하면 오류가 발생하는데, 시험 환경에서는 이런 문제가 없도록 세팅되어 있나요?
일부 옵션들이 보안 및 안정성 이슈로 동작 방식이 변경되었습니다. 그 영향으로 pandas 2.x 환경에서는 inplace 옵션이 기존 1.x 버전과 다르게 작동하거나 오류·경고가 발생할 수 있습니다.
AICE Associate 시험 환경은 교재와 강의가 제작된 시점의 안정화된 라이브러리 버전을 기준으로 구성되어 있어 pandas 2.x 이전 버전 환경에서 시험이 진행되므로 해당 문제는 발생하지 않는다고 이해하시면 됩니다. 다만 향후 시험 환경이 업데이트될 가능성을 고려하면 inplace 옵션에 의존하지 않는 방식으로 작성하는 것이 더 안전합니다.
예를 들어 기존에 df.fillna(0, inplace=True)처럼 작성하던 코드는,
df = df.fillna(0) 형태로 재할당 방식으로 작성하는 것이 버전 변화에 더 안전합니다.
2. 공유주신 모의고사 답안지랑 제 답안지를 비교했을 때 과정은 동일한데 마지막 정확도 및 f1-score 평가에서는 숫자가 일부 다릅니다. 0.1~2정도 차이가 나는데, 어디서 잘못된 건지 확인이 불가합니다. 이렇게 숫자가 완전히 일치하지 않을 수가 있나요?
최근 시험 출제 경향에 맞춰 문제와 데이터를 일부 수정하여 연습하다 보니, 교재에 수록된 모의고사 답안과는 평가 지표 값이 달라질 수 있습니다. 이로 인해 혼란을 드려 죄송합니다.
교재 답안은 출간 당시 기준의 문제 구성과 데이터에 맞춰 산출된 결과이며, 올해 들어 시험 경향에 맞게 문제를 조정하거나 데이터를 변경한 경우에는 랜덤 스테이트를 고정하더라도 정확도나 f1-score가 동일하게 나오지 않을 수 있습니다.
이 경우에는 수치의 완전 일치 여부보다는 문제에서 요구한 전처리, 모델 학습, 평가 방식이 올바르게 적용되었는지를 기준으로 이해해 주시면 됩니다.
혼동을 드린 점 다시 한번 죄송합니다.
3. 추가로 시험 중 오픈북은 주어진 라이브러리에서만 가능하다고 들었는데, 그 라이브러리 홈페이지 안에서 접근 제한된 페이지는 별도로 없는건가요?
시험에서 허용되는 오픈북 범위는 주어진 라이브러리의 공식 홈페이지 기준이며, 라이브러리 문서 내에서 별도로 접근이 제한된 페이지는 없는 것으로 알고 있습니다.
다만, 해당 라이브러리 홈페이지를 벗어나 다른 사이트로 이동하거나, 사이트 내에서 외부 검색·추가 자료를 탐색하는 경우에는 문제가 될 수 있으므로 주의해 주세요.
4. callbacks 관련 함수에서 EarlyStopping은 restore_best_weight=True를 무조건 입력하고, ModelCheckPoint는 save_best_only=True, verbose=1을 무조건 입력해야 하나요?
해당 옵션들은 학습 과정과 결과를 보다 안정적으로 관리하기 위해 강의와 예제에서 자주 사용하다 보니 반복적으로 등장한 것이며, 반드시 항상 입력해야 하는 필수 사항은 아닙니다.
시험에서는 callbacks 옵션을 정해진 형태로 고정해 사용하는 것이 아니라, 문제 지문에서 요구하는 목적에 맞는 파라미터를 선택하여 작성하면 됩니다. 따라서 지문에 특정 옵션이 명시되어 있다면 그에 맞게 작성하고, 별도의 요구가 없다면 필수적으로 넣지 않아도 무방합니다.
5. 모델 측정 지표 결과를 출력 할 때, 강사님의 답안지처럼 print('rfr accuracy ' , accuracy_score(y_valid, rfc_predict))의 형태로 출력해야 하나요?
특정한 요구가 없으면 print(accuracy_score(y_valid, rfc_predict))로 답만 나오도록 출려해도 될까요?
네 이 부분은 제가 파이썬 초보자 분들을 위해 어떠한 값이 어떻게 출력된다는 print 구문으로 작성되어졌다고 보시면 됩니다.
특정 요구가 없다면 해당하는 코드로 작성하셔도 무방합니다.
6. 그리고 파란책 제 2회 모의고사에서 이상치 제거하는 함수 중 df.drop이 아니라 delivery_df.drop이 와야 하는 거 아닌가용?
del_df = df.drop(delivery_df~
이 부분은 제가 작성하다가 실수한 것 같습니다.
말씀해 주신대로 df가 아닌, delivery_df.drop( ~ 으로 작성하는것이 맞습니다. 해당 부분은 수정해 놓도록 하겠습니다.
7. 그리고 아래 코드에서 validation_data = (X_test, y_valid)아닌가요? X_valid는 스케일링 적용 전이고, X_test는 스케일링 적용 후 입니다. 아래는 첨부주신 파란책 제 2회 모의고사 정답 코드입니다. 교재랑 실습 코드 답이 모두 달라서 혼란스러운데, 어떤 것이 답인가요? 감사합니다!
이 부분도 6번과 동일하게 문항과 답을 작성하다 보니 제가 코드를 잘못 넣었습니다.
스케일링 처리한 X_test를 넣는 것이 맞습니다.
8. 아래 답이 RF가 아닌 XGBC인 이유가 있나요? 첨부한 코드 수정없이 엔터해서 값을 불러냈는데accuracy_score는 rf가 더 높고, f1_score는 xgbc가 더 높습니다.이럴 경우 ‘정확도’가 더 높은 걸 선택하라고 할 때 어떤 지표를 기준으로 작성해야 하나요?
어떻게 판단해야 답을 xgbc로 이끌어낼 수 있는지 궁금합니다. 저는 단순히 정확도라고 해서 accuracy_score만을 기준으로 판단하여 rf가 답이라고 생각했습니다.
문항에서는 f1-score와 acc를 이용하여 성능을 비교하라고 했으니 해당 문제에서 해당 지표들에 대한 비교 코드는 무조건 존재해야 합니다.
또한 해당 2개의 지표 중, 정확도(Acc)만을 가지고 비교하라고 진행 했으니 두 모델 중, 정확도가 더 높은 모델을 작성하시면 됩니다.
저는 3회 모의고사 코드들을 다시 진행하였을 때 XGBC의 모델이 정확도가 0.64로 나오고 있긴 합니다.
혹시 코드를 순서대로 치면서 전처리 코드단이 한번 더 실행된 부분이 있지 않을까 싶습니다.
다시한번 커널을 초기화 하신 후 진행하셨을 때 이상이 있으시다면 댓글 부탁드립니다.
9. 해당 문제의 딥 모델 설계 중 model.fit(validation_data=( , ))를 따로 기입하지 않은 이유가 있나용?기입하면 오답 처리하나요?
해당 문제의 지문에서는 model.fit에 validation_data를 사용하라는 명시적인 요구가 없었기 때문에, 정답 코드에서는 이를 기입하지 않았습니다. 시험에서는 문제 지문에 제시된 조건과 요구사항을 기준으로 코드를 작성하는 것이 원칙이며, 지문에 언급되지 않은 파라미터를 반드시 추가해야 할 필요는 없습니다.
10. 혹시 아래에서 pre_df = churn_df.dropna(subset=['years_experience', ‘salary’])대신에
pre_df=curn_df.dropna()만 입력해도 될까요?
앞쪽에서 isna().sum()을 직접 확인해 보니 결측치가 해당 두 컬럼에서만 발생한 상황이라면, 결과적으로는 dropna를 사용해도 동일한 결과가 나오기 때문에 사용은 가능합니다.
다만 시험에서는 문제 지문에서 결측치 처리 조건을 특정 컬럼 기준으로 제시하는 경우가 많기 때문에, 지문에 subset 사용과 같이 조건이 명시되어 있다면 반드시 그 조건을 그대로 반영해 작성하는 것이 맞습니다. 지문에 별도 조건이 없는 경우에 한해 dropna를 사용하는 것이 허용된다고 보시면 됩니다.
11. 아래 모델에서도 validation_data를 따로 기입하지 않은 이유가 있나용? 파란책 기준 제 2회 모의고사에서는 validation_data가 있었는데, 6g회에서는 없네요ㅠㅠ
상황에 따라 다른 것 같은데, 그 판단 기준을 모르겠습니다.
파란책 기준 제2회 모의고사에서는 EarlyStopping과 ModelCheckpoint 콜백을 사용하고 있었기 때문에, 해당 콜백들이 정상적으로 동작하기 위해 validation_data 파라미터가 필수로 포함되었습니다. 반면 이번 문제에서는 해당 콜백을 사용하지 않거나, validation 성능을 기준으로 학습을 제어할 필요가 없었기 때문에 validation_data를 따로 기입하지 않은 것입니다.
validation_data 사용 여부는 문제에서 EarlyStopping, ModelCheckpoint 등과 같이 검증 데이터를 필요로 하는 요소가 포함되어 있는지에 따라 달라진다고 보시면 됩니다. 이 기준에 대한 설명을 강의에서 충분히 드리지 못한 점, 혼란을 드려 죄송합니다.
12. 혹시 해당 코드에서 원본 보존을 위한 코드를 따로 치는 이유가 있나요?
이전 파란책 모의고사에서는 원본 보존없이 바로 fillna와 drop을 수행했는데, 해당 모의고사에서는 왜 원본 보존을 위한 코드가 들어갔는지 궁금합니다.
원본 보존 코드를 포함한 것은, 시험 중 전처리 과정에서 발생할 수 있는 실수를 줄이기 위해 원본을 보존하는 습관을 들이라는 취지로 작성된 것입니다. 문항들이 이어지는 구조의 시험에서는 한 단계에서 데이터가 잘못 처리되면 이후 문항 전체에 영향을 줄 수 있기 때문에, 원본을 유지한 상태에서 복사본을 기준으로 작업하는 방식이 도움이 됩니다.
시험뿐만 아니라 실제 분석 환경에서도 동일한 방식이 자주 사용되므로, 해당 모의고사에서는 이러한 작업 습관을 익히도록 구성되었다고 이해하시면 됩니다.
13. 빨간책 1회 모의고사 13번 문제 (딥러닝 설계)입니다
13.1) 문제 모델구조 중 가장 마지막에 ‘출력층 : Dense 레이어, 1개 노드(가격을 예측하므로)’라고 되어 있습니다.
그에 대한 답으로 강의에서는 model.add(Dense(1, activation = ‘linear’))이라고 입력했고, 교재에서는 model.add(Dense(1))이라고만 입력되어 있습니다. 둘 다 동일한 건가요? 다르다면 어떤 것이 정답인가요?
회귀 문제에서 출력층으로 사용하는 Dense 레이어는 기본 활성화 함수가 linear이기 때문에, Dense(1)과 Dense(1, activation='linear')는 동작상 동일합니다. 강의에서는 출력층의 의미를 명확히 설명하기 위해 activation을 명시적으로 작성한 것이고, 교재에서는 기본값을 사용해 간단히 표현한 차이입니다.
따라서 두 방식 모두 문제에서 요구한 모델 구조를 충족하며, 시험에서도 어느 한 쪽만을 정답으로 제한하지는 않습니다. 지문에서 활성화 함수를 별도로 지정하라는 조건이 없는 경우에는 Dense(1)로 작성해도 무방합니다.
14. 이어서, 실전 책 1회 14번에서 predicted_price가 인강에서는 1211.2705로 산출되었는데 첨부주신 정답 코드 파일에서는 91.90으로 나옵니다. 왜 가격이 달라졌는지 궁금합니다 ㅠㅠ
2번 질문에서 답변드린 것 처럼 이번에 전체적으로 문제 및 데이터를 고도화를 위한 작업을 진행하다보니 값이 틀려지게 되었습니다. 이 부분도 혼란을 드린 점 죄송합니다.
댓글을 남기려면 로그인하세요.