AICE Associate 3회 모의고사 12번, 14번 정답 / AICE Associate 4회 모의고사 3번 정답관련 질의 / AICE Associate 4회 모의고사 8번, 11번 정답관련 질의 / / AICE Associate 6회 모의고사 4번, 9번 문제 관련 질의
<AICE Associate 3회 모의고사 12번>
동영상에서는 강사님이 정답이 ‘RF’라고 하시고, 실제 도서랑 전달해주신 답지에서도 ‘XGBC’라고 하셔서
답이 상이하게 설명하셔서 혼란이 옵니다.
rfc_acc: 0.632
xgbc_acc: 0.604
rfc_f1: 0.02127659574468085
xgbc_f1: 0.24427480916030533
정확한 정답이 무엇이며 Accuracy_score, F1_score볼 때 더 좋은 모델이라고 판단하는 기준은 무엇입니까?
f1_score 비교하면 명확히 정답은 ‘XGBC’인 것 같은데욤..ㅠ
<AICE Associate 3회 모의고사 14번>
강의에서는 주어진 함수인 simul_data를 활용하시지 않으시고
deep_pre = model.predict(X_test) 라고 하시더라구요.
그냥 정답은 교재정답과 같이 simul_data를 이용해야하니까 deep_pre = model.predict(simul_data)가 맞죠?
<AICE Associate 4회 모의고사 3번>
mpg_df.rename(columns={'mpg':'연비', 'cylinders': '실린더 수', 'displacement':'배기량', 'horsepower': '마력', 'weight': '차량 무게', 'acceleration': '가속 성능', 'model_year':'차량 출시 연도', 'origin':'제조 국가 코드', 'name':'차량 이름'}, inplace = True)
실제로 강의도 그렇고 정답도 그대로긴 한데, 실제로 쳐보면 다른건 다 한글로 바뀌는데 mpg는 한글로 변경이 안되어있더라구요. 그래서 저걸 입력하기 전에 mpg_df.reset_index(inplace=True) 이걸 코듸치니까 mpg가 한글로 변경되던데.. 이렇게 하면 됩니까?
<AICE Associate 5회 모의고사 8번>
X = churn_df_clean.drop(columns = ‘attrition’)
y = churn_df_clean[ ‘attrition’]
도 정답 틀린 것 같습니다. churn_df_clean이라는 데이터 자체 생성하라는게 없었습니다.
이 문제 앞 전에서 encoing_df 다중인코딩한 데이터를 만든 상황에서 Feature/Target 분리하는거니까
X = encoding_df.drop(columns = ‘attrition’)
y = encoding_df[ ‘attrition’]
이게 정답 아닌가요?
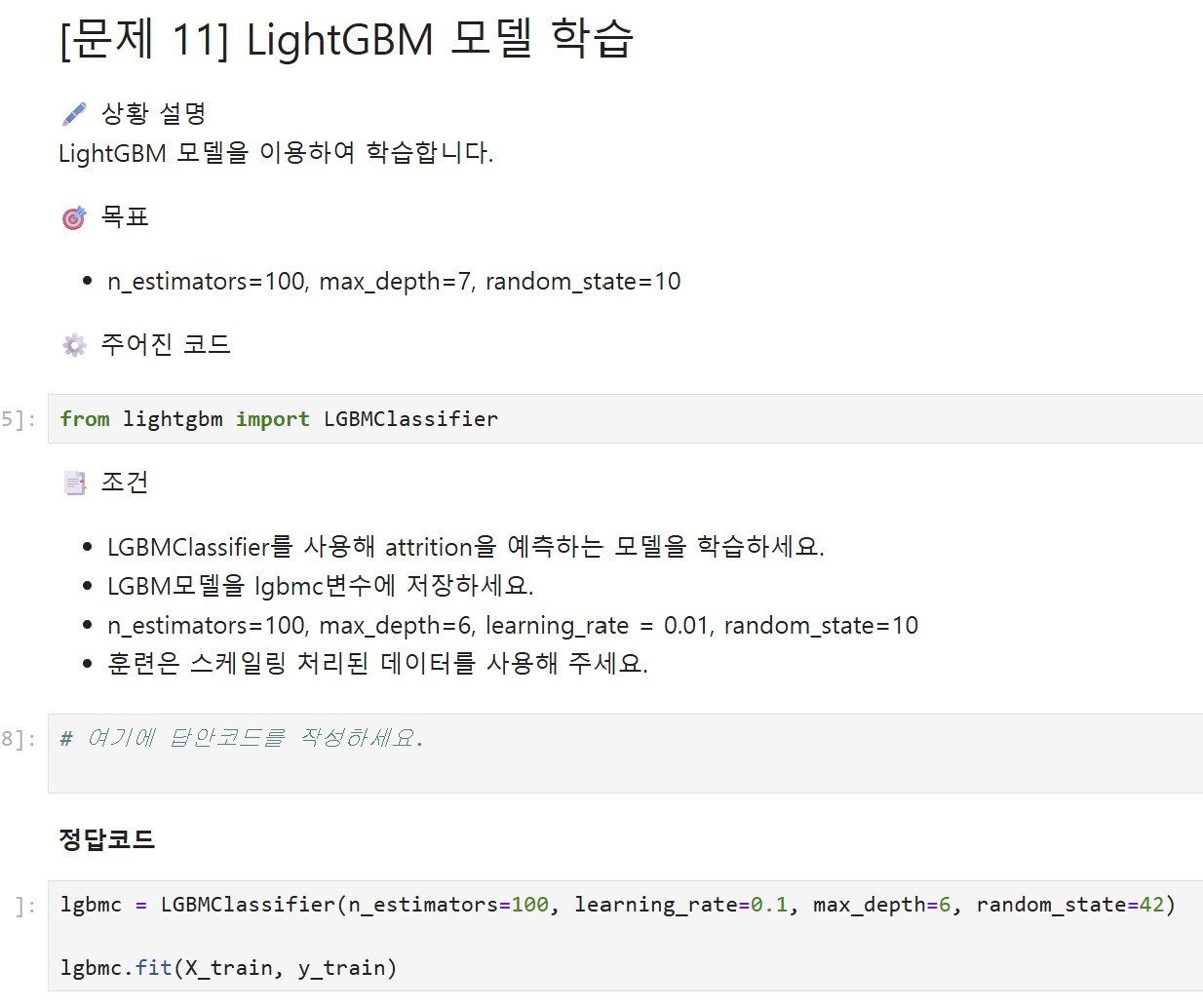
<AICE Associate 5회 모의고사 11번>
lightgbm 깔아서 LGBClassifier을 했는데, 교재와 지문에서는 learning_rate = 0.01 인데 정답에선 0.1로 제시되었고 강의에서도 0.1로 치고 진행하시더라구요. 그냥 0.1로 진행하면 되나요?
<AICE Associate 6회 모의고사 4번>
telecom_csv를 불러와 telecom_df 데이터를 만들었는데
4번에서는 왜 문제 풀기 전에 넣는 코드에
뜬금없는 churn_df를 왜 결측치 처리하라고 지문이 나와있나요??? 문제 오류아닌가요?
In [ ]
churn_df'연령'].fillna(churn_df['연령'].'<문제3-1>', inplace = True)
churn_df'지역'].fillna(churn_df['지역'].'<문제3-2>', inplace = True)
<AICE Associate 6회 모의고사 9번>
해당 지문 코딩을 하면 에러가 계속 뜹니다. 뜬금없는 concat함수에 심지어 지문에 나와있는 X_train_sacled 자체가 데이터프레임 형성 오류가 뜨는데….. -_-;;;
진짜 넘 오류가 많아서 집중하기 너무 어렵습니다. 실전같이 풀려고 해도 맥이 끊겨요
댓글
안녕하세요, 질의 주셔서 감사합니다.
문의주신 항목들에 대해 순서대로 답변드리겠습니다.
3회 모의고사 12번
해당 문항은 이후 데이터와 문제 내용에 수정이 반영되면서 강의 영상과 최신 교재 및 답지 간 결과가 다르게 보인 부분이 있었습니다. 현재 기준으로는 Accuracy 기준으로 모델을 평가하는 문항이므로 RF가 정답입니다. 다만 문의주신 것처럼 Accuracy score와 F1 score가 서로 다르게 나타날 수 있기 때문에 혼란이 있을 수 있습니다. 해당 문항은 정확도를 기준으로 판단하는 문제이므로 RF를 정답으로 보시면 됩니다.
3회 모의고사 14번
말씀하신 내용이 맞습니다. 해당 문항은 주어진 simul_data를 활용하는 문제가 맞기 때문에 deep_pre = model.predict simul_data 형태로 작성하는 것이 올바릅니다. 강의에서 X_test를 사용한 부분은 설명 과정에서의 예시로 보이며, 문항 기준 정답은 simul_data를 이용하는 방식이 맞습니다.
4회 모의고사 3번
해당 부분은 mpg 컬럼이 인덱스로 처리되어 rename이 적용되지 않은 것으로 보입니다. 따라서 말씀해주신 것처럼 reset_index를 통해 컬럼으로 되돌린 뒤 rename을 적용하시면 정상적으로 변경됩니다.
5회 모의고사 8번
말씀해주신 내용이 맞습니다. 해당 문항 흐름상 이전 단계에서 encoding_df를 생성한 뒤 이를 기준으로 Feature와 Target을 분리하는 것이 자연스럽기 때문에 X = encoding_df.drop columns = attrition, y = encoding_df attrition 으로 작성하는 것이 맞습니다. churn_df_clean을 사용하는 정답은 문맥상 맞지 않으며 수정이 필요한 부분입니다.
5회 모의고사 11번
교재와 문제 지문에 제시된 내용이 기준이므로 learning_rate는 0.01로 설정하는 것이 맞습니다. 해당 문항은 지문에 제시된 값을 그대로 반영하여 풀이하는 것이 올바르며, 이전 답변 과정에서 혼선을 드린 점 양해 부탁드립니다.
6회 모의고사 4번
이 부분은 문제 오류로 보는 것이 맞습니다. telecom_csv를 불러와 telecom_df를 생성한 상황이라면 이후 결측치 처리 역시 telecom_df를 기준으로 진행되어야 하는데, 지문에 갑자기 churn_df가 제시된 것은 앞뒤 문맥상 맞지 않습니다. 따라서 해당 코드는 telecom_df 기준으로 수정되어야 맞습니다.
6회 모의고사 9번
문의주신 내용만으로는 정확히 어떤 원인으로 에러가 발생하는지 판단하기 어려운 부분이 있습니다. 특히 concat 함수 사용 과정이나 X_train_scaled 데이터프레임 생성 과정에서 어떤 오류 메시지가 출력되는지에 따라 원인이 달라질 수 있습니다. 해당 부분은 발생한 에러 문구를 구체적으로 전달해주시면 보다 정확하게 확인 후 도움드리도록 하겠습니다.
혼선을 드린 점 양해 부탁드리며, 세부적으로 확인해주셔서 감사합니다.
꼼꼼하게 답변 주셔서 감사합니다.
6회 모의고사 9번에서 해당 지문 에러난건 해결했습니다.
제가 7번 붬주형 변수 인코딩할 때,
telecom_df = pd.get_dummies(telecom_df, columns = ['지역', '계약유형'], drop_fist = True)를 넣었는데… drop_first = True를 삭제하니까 지문 코드가 에러없이 인식되더라구요.
그래서 궁금한게 인코딩할 때, drop_first를 해야하는 상황과 해애히지 않은 상황은 어떻게 구분해야하나요???
drop_first 가 카테고리 하나 제거해서 중복 정보 없앨 때 사용한다고 하는데… ㅠ
안녕하세요 질의주셔서 감사합니다.
drop_first=True는 더미 변수 생성 시 기준이 되는 카테고리 하나를 제거하여 중복 정보를 줄이기 위해 사용하는 옵션입니다.
다만, 이 옵션은 반드시 사용해야 하는 것은 아니며 상황에 따라 선택적으로 적용하시면 됩니다.
일반적으로 회귀분석이나 로지스틱 회귀처럼 선형 모델을 사용할 때는 다중공선성을 방지하기 위해 drop_first=True를 사용하는 것이 좋고, 트리 기반 모델(의사결정나무, 랜덤포레스트 등)이나 단순 전처리 단계에서는 drop_first를 사용하지 않아도 큰 문제가 없습니다.
또한, 문제에서 제공된 코드나 이후 과정과 맞지 않는 경우에는 drop_first=True 사용 시 오류가 발생할 수 있으므로, 지문 코드와 동일하게 맞추는 것이 가장 안전합니다.
댓글을 남기려면 로그인하세요.