먼저 학습 과정에 혼란을 드려 정말 죄송합니다. 확인해보니 데이터 표준화 단계에서 X_valid를 transform한 값을 X_test 변수에 저장하도록 안내되어 있었는데, 이후 딥러닝 모델 학습 코드의 validation_data에는 스케일링된 X_test가 아니라 원본 X_valid가 들어가 있어 변수 사용이 일관되지 않았습니다. 따라서 해당 흐름에서는 validation_data=(X_test, y_valid)로 작성하는 것이 맞으며, 또는 표준화 단계에서 X_valid = scaler.transform(X_valid)로 저장한 뒤 validation_data=(X_valid, y_valid)로 사용하는 방식이 더 자연스럽습니다.
댓글
안녕하세요. 질의주셔서 감사합니다.
먼저 학습 과정에 혼란을 드려 정말 죄송합니다.
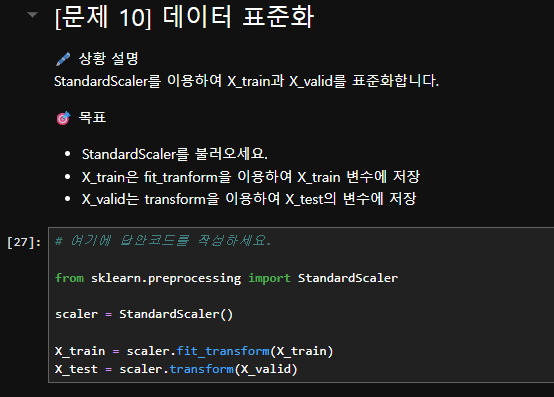
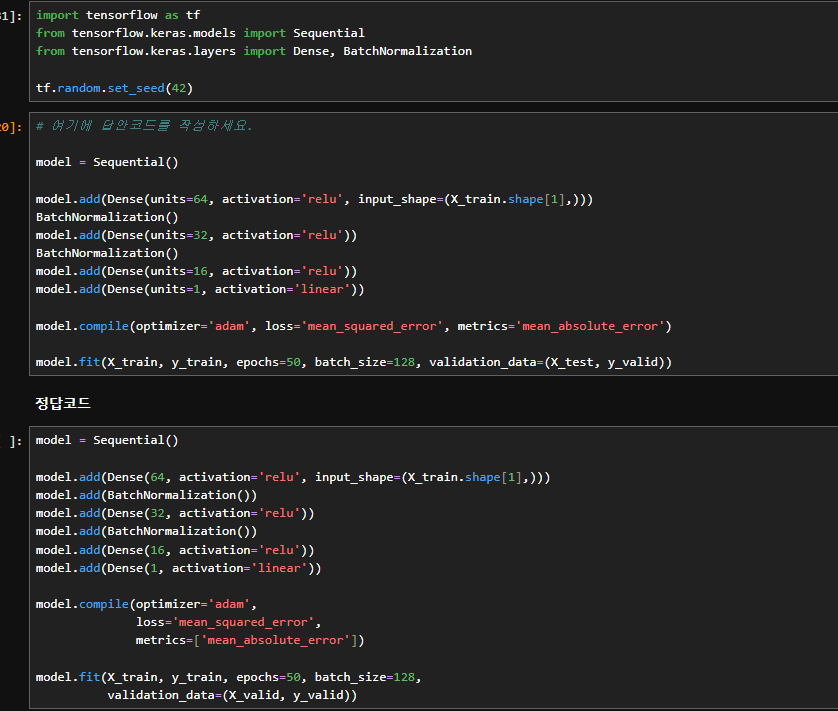
확인해보니 데이터 표준화 단계에서 X_valid를 transform한 값을 X_test 변수에 저장하도록 안내되어 있었는데, 이후 딥러닝 모델 학습 코드의 validation_data에는 스케일링된 X_test가 아니라 원본 X_valid가 들어가 있어 변수 사용이 일관되지 않았습니다.
따라서 해당 흐름에서는 validation_data=(X_test, y_valid)로 작성하는 것이 맞으며, 또는 표준화 단계에서 X_valid = scaler.transform(X_valid)로 저장한 뒤 validation_data=(X_valid, y_valid)로 사용하는 방식이 더 자연스럽습니다.
댓글을 남기려면 로그인하세요.